AI for Enterprise Data Recovery


Part 1: Problem Statement and Proposal
The Problem: When Traditional Backup Strategies Fall Short
More often than not, we see that enterprise analytical platforms face a fundamental challenge in the modern data landscape: how to recover vast amounts of user-generated analytical data without breaking the budget. Traditional backup-and-restore approaches, while reliable, create a hidden financial burden that has become unsustainable for data-intensive organizations especially as we reach the exabyte limits.
Consider a typical enterprise analytical platform storing ~100PB of analytical data. Using conventional backup strategies, organizations must maintain duplicate storage infrastructure, resulting in annual costs of approximately $15M to $35M just for data protection depending on the different recovery tiers they sign-up for. This essentially means that the the total cost of storage after including back-ups is close to ~(1.3 - 2x) of the primary storage , not accounting for backup compute resources, network transfer costs, and extended recovery times that can stretch into days or weeks.
The core problem extends beyond cost. Traditional approaches treat all data equally, backing up everything regardless of criticality or regenerability. This creates several critical limitations:
- Indiscriminate data protection that backs up both irreplaceable source data and derived analytical datasets that could be recreated
- Extended recovery times measured in hours or days, causing significant business disruption
- Non-existent recovery prioritization: With traditional monolithic backups, it is difficult to restore only the business-critical data first.
- High storage overhead requiring ~2x storage capacity for complete protection
- Limited granularity with point-in-time recovery that may lose hours or days of analytical work
- Manual dependency resolution that introduces human error and extends recovery time
These challenges are particularly acute for analytical platforms where much of the valuable data consists of user-generated queries, transformations, and derived datasets built from core source systems that already have their own backup and recovery mechanisms.
To be fair, the reason traditional backups are so monolithic is because it's nearly impossible to manually classify daily user data as business-critical or non-critical in real-time at scale. Even if you do have a system, the likelihood of user classifying all data as critical is high which defeats the purpose.
Proposed Solution: AI-Powered Query Replay Agents
Instead of backing up everything, what if we could intelligently recreate user-generated data by replaying the queries and transformations that created it? This fundamental shift in thinking forms the foundation of our AI-powered query replay agent approach.
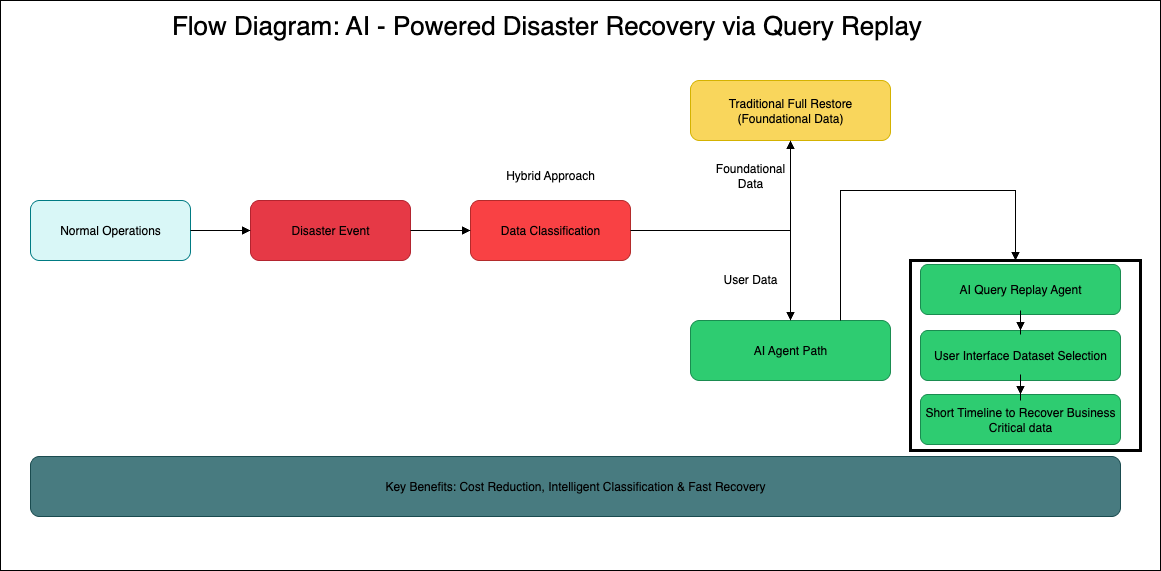
Cost Optimization: Eliminate the need for duplicate storage infrastructure by focusing on query replay rather than data duplication. Potential savings of 60-65% compared to traditional backup costs.
Precision Recovery: Achieve query-level recovery granularity, recreating exactly what was lost without the data loss inherent in point-in-time snapshots.
Intelligent Prioritization: Use AI to classify datasets by criticality and dependencies along with user-driven selection to ensure critical data is recovered first, but user preferences shape the overall recovery flow , ensuring that essential data is recovered first while non-critical analytics can be deprioritized.
- Personalized User-Controlled Recovery Experience: The agent presents a catalog of user-created datasets with metadata, dependencies, and lineage—all visible to the user. Users can then:
- Select datasets, views, or queries they want recreated
- Skip recovery for less important data
- Defer recovery for large, low-priority analytics
Automated Dependency Resolution: Leverage graph algorithms and machine learning to understand complex data relationships and execute recovery in the optimal sequence.
Business-critical Rapid Recovery: Reduce recovery time objectives from days to minutes with very little business impact by executing parallel query replay operations across distributed computing resources for the business critical data.
Scope Definition:
In Scope: Analytical Data Recovery
Our AI-powered query replay agent framework specifically addresses the recovery of user-generated analytical data in large enterprise data warehouses and lake houses. This includes:
- Derived datasets created through user queries and transformations
- Analytical views and aggregations built from core data sources
- Machine learning feature stores and processed datasets
- Business intelligence data marts and reporting datasets
- Ad-hoc analytical outputs from data science workflows
The focus is on data that can be logically recreated by understanding and replaying the analytical processes that generated it, rather than data that requires bit-level restoration.
Out of Scope: Infrastructure and Source Systems
We are not attempting to solve:
- Predictive failure detection or automated backup triggering
- Infrastructure disaster recovery or system-level restoration
- Source system backup and recovery (these have existing solutions)
- Real-time operational data protection for transactional systems
- Complete database restoration for primary operational systems
The agent assumes that foundational data sources (operational databases, external feeds, etc.) have their own robust backup and recovery mechanisms in place.
Key Differentiator: Cost vs Coverage Trade-off
Traditional approaches prioritize comprehensive coverage at any cost. Our approach optimizes for intelligent selectivity and cost efficiency. We're specifically targeting scenarios where:
- Storage costs represent a significant budget constraint
- Much of the data can be logically recreated from source systems
- Critical Data Recovery speed is more important than point-in-time precision
- Organizations are willing to trade some coverage for substantial cost savings
Based on my research, while some vendors are incorporating AI into storage management & backup solutions , none are pursuing the query-replay approach for analytical data. If there are any that you have encountered then please share the same.
Key Risks and Mitigations
While the AI-powered query replay approach offers significant advantages, executives should understand the key risks and how they're addressed:
Risk 1: Query Dependency Complexity
Challenge: Complex data transformations may have hidden dependencies that could cause replay failures.
Mitigation: Advanced graph analysis and machine learning models map both explicit and implicit dependencies. Comprehensive testing validates dependency chains before production deployment.
Risk 2: Source System Availability
Challenge: Query replay requires source systems to be operational and accessible.
Mitigation: The approach assumes foundational systems have robust DR capabilities. Hybrid model ensures core operational data remains protected through traditional methods.
Risk 3: Recovery Time for Complex Analytics
Challenge: Large, complex analytical processes might take significant time to replay.
Mitigation: Intelligent prioritization recovers business-critical data first. Users can defer non-essential analytics and leverage parallel processing for complex queries.
Risk 4: Data Quality Validation
Challenge: Ensuring replayed data matches original analytical results.
Mitigation: Automated validation frameworks compare key metrics, checksums, and business rules. Quality gates prevent incomplete recoveries from reaching production.
Risk 5: Skill Requirements
Challenge: Implementation requires expertise in AI, metadata management, and query optimization.
Mitigation: Phased implementation approach allows skill development. Partnership with technology vendors provides expertise during initial deployment phases.
Bottom Line: These risks are manageable through proper implementation, testing, and hybrid approaches that maintain traditional backup for truly critical operational systems.
Conclusion Summary
The AI-powered query replay agent represents a fundamental paradigm shift in enterprise data recovery strategy. Rather than treating all data equally through expensive, monolithic backup approaches, this intelligent framework recognizes that most analytical data can be recreated more efficiently than stored.
The core insight: In petabyte-scale analytical platforms, 60-80% of data consists of user-generated queries, transformations, and derived datasets that can be logically recreated from foundational systems that already have robust backup mechanisms.
Blog Series Overview: A Four-Part Journey
This comprehensive exploration of AI-powered disaster recovery will unfold across four detailed technical blog posts, each building upon the previous to create a complete understanding and implementation guide.
Part 1: Problem Statement and Proposal (This Post)
Focus: Establishing the business case and conceptual foundation
Part 2: Technical Framework and Architecture (Week 2)
Focus: Deep dive into the technical architecture and implementation framework
Part 3: Building and Deploying the Agent (Week 3)
Focus: Hands-on implementation with working code and demonstrations
Part 4: Testing, Results, and Production Insights (Week 4)
Focus: Testing criteria, results and production deployment guidance
For organizations currently spending millions annually on traditional data protection, this series offers a roadmap to dramatically reduce costs while improving recovery capabilities. The combination of artificial intelligence, modern distributed computing, and intelligent data management creates new possibilities for enterprise resilience that were simply not feasible with previous generations of technology.
Coming Next Week: Part 2 will provide a comprehensive technical deep dive into the framework architecture, exploring the specific technologies, integration patterns, and AI/ML implementations that bring this concept to life.